I'm seeing a steady increase in the number of software and online translation projects we handle for the English to Korean language pair.
At the same time, I've noticed that client and translator expectations about budgets, processes and client-vendor involvement are not always in sync with the difficulties these projects present. In addition to lack of context, programming codes embedded in text and other technical challenges of the translation process, differences between languages in terms of structure and cultural and grammatical interpretations of the written word can easily confuse matters and introduce serious errors that impact the final product. Since the differences between English and Korean (both linguistically and culturally) are much greater than those between Western languages, the translation and localization of English to Korean is particularly challenging.
Typical inquiries for software localization work often sound like the following: “Translations must be completed in our online interface within six hours. There’s no guarantee of volume or minimum fees. The material would be tech in nature (software).” or "We've got an Excel spreadsheet of phrases here for translation by tomorrow morning and our budget is $XX. Be careful not to mess up the coding in the text. And make sure you check your work."
Amazingly, the first project request mentioned above came in for work that was to be provided to a large software company. And is a final exhortation to "check your work" a way for the client to try to get something for nothing? Does that mean we don't check our work otherwise?
When translation is regarded as an afterthought to be taken care of as fast and cheaply as possible by whoever happens to be available at the time — and sometimes in as few steps as possible — is it any wonder that I keep finding errors in the Korean versions of leading software and online interfaces from tech names like Microsoft, Google and Instagram?
The standard localization process involves three basic steps. The source text is first translated into the target language by a single translator. Then, a second linguist proofreads the translator's work. Finally, the proofread translation is placed into the software or online interface (or if printed materials, then a design program, such as Illustrator or InDesign) and reviewed in-context by a linguist (possibly the original translator or proofreader) to catch final errors.
There can be slight variations in this workflow, such as the inclusion of reference files and special localization-related instructions at the beginning, translator questions along the way, sending back of the proofreader's changes to the translator for re-verification and/or a second post-layout proof. But these three steps remain as the underlying workflow in most translation processes we work on.
I've identified a number of key failure points in this workflow though, and I believe the explanations and examples presented below demonstrate that the standard process is not up to the task of producing the highest quality work on a consistent basis for English to Korean localization work.
Some of my recommendations demand higher budgets, but new approaches with the latest software can also achieve enhanced efficiency through proper up-front preparation, more (and more effective!) ongoing communication between the client and translation team to work out issues, redesigned workflows with a new linguist role (that of the Korean-speaking tech-savvy English native-speaker who functions as the central point around which the process runs) and a longer schedule for all the back-and-forth.
Failure Point #1 – Ignoring the impact of inter-language sentence structure differences on translation
Software often includes text with embedded variables for which values are to be inserted dynamically to create complete sentences that are then shown to users during use. Here's an example of what we might be asked to translate:
Segment 1: <b>In any given single month over the coming one year, how likely are you to buy at least ^f('X5').
Segment 2: toNumeral()==23?"Y300":"$10"^ from an online store, such as ^pineOrp()^?</b>.
* Text altered to protect client confidentiality.
When translating from English to Korean, more often than not, the sequence of variables may have to be moved around (assuming the translators even know what the variables mean). Also, when sentences are broken into segments like this, it's seldom possible to translate the parts individually; they have to be translated as a whole and then resegmented.
In some cases, the spellings of words can impact other text in a sentence, too. For example, in English, inserting a person's name can affect the gender of pronouns elsewhere in the sentence. And a variable for a noun may require either an "a" or "an" before it, depending on whether the first letter is a vowel or a consonent. These issues have to be taken into account when writing the English sentences but this effort does not necessarily transfer in translation as there are completely different complications that might crop up in Korean, such as the impact of spellings on surrounding grammatical tags. (See Here's Why You Can't Blindly Search-and-Replace in a Korean Text.) Even just asking for someone's first name and last name on a Korean form will get everything backward from the English!
Here is a sentence from my Korean Translation Buyer's Guide to illustrate just how different the sentence structures are between English and Korean:

What all this means is that the effort to get things right when variables are embedded in the text can be significant. It requires adequate budget for the time taken, as well as responsiveness from the client, and a translation team that is attentive and patient enough to identify and point these issues out and consider solutions, even at the cost of interrupting the workflow.
The translation of texts that consist of fragments of English sentences to be translated individually should be avoided at all cost. Without proper advance planning and ongoing effort, these texts usually result in nonsensical translations since it's not always possible to identify word-for-word correspondence from language to language. Here's an extreme example (with the text altered to protect client confidentiality) we were asked to translate recently.

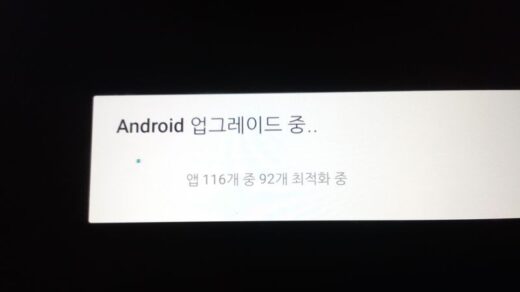
Example Error from Google
Recently I discovered an error on the Google Android phone which illustrates this very problem. When uploading photos from the phone, I got the message (in Korean), "uploading 344 of a total of 200 [photos]” when it should have said something like “Uploading photo 200 of a total of 344 photos.” In other words, the numbers were switched.
- For my original article about this, see There's a Translation Error in the Korean-Language Google Android Interface!
The mistake would have occurred when the English source provided to the translation team consisted of the GUI text with coded variables embedded for the numbers. The translator should have switched the variable sequence to match the Korean sentence structure, but for one reason or another (possibly because of software limitations), the English order was maintained in error. Even when sequencing can be maintained, it frequently results in awkward wordings or confusion for the end user.
Rethinking the Process
Every sentence which contains variables needs to be reviewed to check for issues. If the meaning is unclear or if there are word order or other considerations, such as potential changes to the surrounding text caused by certain potential variable values, the translation team should discuss with the client about the impact this has on the translation.
In my experience, these issues are not always obvious before starting the job; it is only after much work has been done that awkward translations become evident. Therefore, while an initial review of the document should take place to be sure the issues won't be excessive, the really careful check can be part of a later review by a native speaker in the source language who also knows the target language.
Some jobs just aren't doable. The London fog example above was part of a huge project to localize an ESL program to Korean. There were so many issues with the job (even beyond the example provided) that I had to refuse the work as, to do it right, would have required a translation team to be embedded in the client's office for weeks to work painstakingly through the text. Some projects just aren't conducive to an outsourced approach, even though an in-house approach is unworkable or cost prohibitive.
Failure Point #2 – Attempting to translate long lists of words and phrases without adequate context
Translators need to work from context and it is not realistic to expect a perfect translation of just an Excel spreadsheet or Word document with nothing more than long lists of words and phrases to be translated. Without context, even the best translator will not always be able to figure out how a word or phrase is to be used.
Just telling a translator to send back a list of questions for clarification may also not be enough because there's no guarantee that a translator will know that he or she has misunderstood something. And (to be really frank here), translators hate to interrupt their workflow with this stuff, and so the temptation to just translate and move on can be compelling.
In fact, even though translations into Korean should be done by native Korean speakers, I've found that as a native English speaker, I'm often in a better position than my Korean team to grasp the nuances of the English source text and detect mistranslations or identify questions to ask the client. I also find that these issues jump out at me more vividly after I've received the translation from my team, not before the work starts, since I can see how the text was understood (or misunderstood) by my team and make a comparison.
And finally, I am often dismayed to see that clients do not recognize the challenges non-native English-speaker translators face and are not interested in getting involved. For example (to take an actual issue we encountered not long ago), it takes a pretty nuanced understanding of English to know that "property" can refer to real estate or the sum of one's assets; but "properties" is only real estate. Fortunately, by adding my additional role to the process, I can take care of many issues myself without going to the client for clarification, helping to reduce the burden on both the translators and the client.
Example Error from Microsoft
Here’s another example of what can happen without context. The following phrase in the Korean version of Windows 8 appeared when trying to use the camera app while a camera was not connected to the computer:
“카메라를 연결합니다”
When I first saw this message, I thought the computer was telling me to wait while it connected to a webcam (although the Korean text used here isn't exactly right for that situation either). However, based on the context (which is made doubly clear because the options on the screen are grayed out pending a camera connection), the Korean text should be a command telling the user to connect a camera in order to use the application.
In this case, the Korean text has a meaning more along the lines of a declarative sentence describing the action of connecting a camera because the translator understood "connect a camera" as an infinitive phrase (e.g. the phrase "to connect a camera" in English) rather than a command.
- For my original article about this, see I Upgraded to Windows 8 Last Night… and I Already Found a Translation Error in the Interface.
Rethinking the Process
Translating word and phrase lists properly takes considerably longer than working in normal prose. That's because word and phrase lists don't serve as their own context like ordinary text does, and so a careful translator referencing client explanations, screenshots and other materials will spend longer than normal on the work. Sure, a translator can rush through, but without having and using additional reference information, there are likely to be some mistakes, possibly many.
In my experience, issues with a lack of reference material can be greatly alleviated through a careful review by a native English-speaker Korean translator (i.e. someone like me) after the translation has been completed by the Koreans. This is an important value-add for identifying problems and potential issues to be discussed with the translation team and/or the client; or even for solving problems without bothering the client. However, while this additional review step can reduce the requirements on the client to provide context and respond to questions, it takes a lot of time to manage the communications with the client and translators.
Failure Point #3 – Focusing on budget and turnaround without considering the ROI
In addition to support from the client and effectiveness of the workflow, the quality of a translation project rests also on the basic translation skills of the linguists, their fluency with the subject matter, their ability to work in the tools and their effort and aptitude to do a good job. When you consider that even a premium translation effort represents only a fraction of the total cost that an end client puts into developing their materials and the fact that the accuracy of a translation can ultimately make or break the ROI of a localization project, it would seem that cost should only be one factor in the decisions about resources and workflow.
Unfortunately, I get, on a daily basis, BCC emails sent out by agencies to umpteen translators at a time offering texts to be translated or proofread on a rush basis and at rates that don't attract my attention. Furthermore, the fragmented way these jobs are sent out means there's little to no continuity between tasks and this compromises the final output in various ways, particularly in terms of consistency.
I will also use this as an opportunity to point out that hourly rates for editing and proofreading fall below what skilled Korean>English translators can earn on per-word translation work. This means that review work is often handled by lesser or beginner resources and avoided by veterans. I haven't figured out the entire dynamic here, but there seems to be a lot more client tolerance for proper rates at the early stages of the process than the end, especially when the rates can be expressed in units of word output rather than units of time input. (For a bit more of my soapbox here, see Ten Reasons to Avoid Proofreading, Editing and QA Tasks on Korean Translation Projects.)
Example Error from Google
Consider the following awkward Korean phrase I discovered on the camera help screen of my Android phone and what it would convey if written in English:
“인물 단체는 베스트페이스 모드를 이용합니다.”
“Use Best Face mode for [taking photos of] groups of humans.”
Humans? How about "people"? In fact, the problem is even worse than this because the rest of the Korean translation is poorly written, too. The English on-screen documentation had gems like the following: “It provides best picture automatically changing scene mode in according with the environment”.
Either the Korean was poorly translated from bad English or both were translated from a third language by the camera's supplier and the translators or writers working on the project were not competent in either language.
- For my original article about this, see It's Time for Another Korean Translation Error in the Google Android Interface.
Rethinking the Process
Putting together a good localization team means working with translators who can and will make the effort required. But it's not just about more money. Translators skilled in CAT tools (such as Trados or memoQ) and other technical skills to use the software, as well as experience in the field, are able to bring higher efficiency to the process and often deliver large jobs at lower rates than expected after considering volume and fuzzy/rep/match discounts. They also meet deadlines. This means that focusing on the base rate quoted for a job does not always take into account the real costs.
Furthermore, improved workflows can extract more value from less effort. But even the best translators may still slide into "good enough" workflows if better ideas and structures are not provided. Unfortunately, many client-imposed structures are so fragmented and cumbersome due to a lack of Korean-language skills at the project management level that efficiency, quality and consistency are all compromised. I believe that smooth end-to-end outsourced workflows from the Korean provider would add value in many ways. Those are the processes I am working to develop with my team to deliver even better quality to clients, even while cutting out the fat of inefficiency.
Failure Point #4 – Not considering the importance and difficulty of maintaining consistency
There is almost always more than one correct way to translate the same text, but if a project is handled as a sequence of independent sub-projects, if multiple translators are working simultaneously on different sections of the same job (even if accessing an online TM together), if a translation team is switched in the middle of a project — or even if a translator working alone doesn't make the effort to use the latest tools diligently throughout a single project — inconsistencies can creep in, both in terms of terminology and style, especially if the client isn't in a position to to demand rigorous accountability. These inconsistencies can be hard to prevent, difficult to find and nearly impossible to remove later on.
A project style guide is good, as is a glossary. Both should be prepared at the beginning of a project. And translators should always be provided with previous translations handled for the same client or project as reference. But with today's tools like Trados Studio or memoQ, there are also lots of other ways to improve consistency, such as with a proper termbase, use of the concordance function, LiveDocs (in memoQ) and the built-in Q/A checkers of the various CAT tools. (At this point, I don't know if machine translation plug-ins can make constructive contributions to the process for Korean and English.)
Unfortunately, at least with the English to Korean language pair, there are very few translators who have the software AND know-how to use it beyond the basic functions AND are all that interested in working through the complicated processes of setting up and using all those extra files and windows while translating. You can clearly see how unimportant Korean is to the CAT tool makers by counting how many of these software interfaces and help files are available in Korean: zero, as far as I know. The resistance I get from my resources when it's time to upgrade and learn new ways of working shows me that the local Korean translation market does not demand proficiency in CAT technology.
Example Error from Instagram
What happens when consistency is lost? Consider the following sequence of Korean text in the Android Instagram app: “공유하기”, “삭제”, “사람 추가” and “복사 공유 URL”
The first of the four items was translated into Korean using a style that is different from the other three. In the English interface, the four phrases appear as "Share," "Delete," "Add People" and "Copy Share URL" in the imperative form, each line starting with a verb. In other words, the grammar of the English text is written consistently and correctly while the grammar of the Korean text is not.
- For my original article about this, see Instagram Is Not Immune from Korean Translation Errors Either.
Rethinking the Process
It has become clear to me that I'm not in a position to expect high levels of CAT-tool competency from the full field of English to Korean translators I work with in Korea. But limiting our work only to those who are skilled in Trados means missing out on some of the very best linguists for the technical fields we handle.
Fortunately, I am also realizing that everybody on the team doesn't need to know how to use the advanced tools of our trade. One central player in the process who is proficient in the tools can cover for a team of competent translators who utilize just the basic CAT-tool functions (or don't even use them at all, sometimes).
This person (a native English-speaker) can start things off with a good glossary, prepare the files into packages for use by the translators using the professional version of the software so that the translation environment is set up in advance for the translators, review the translation with a native English-speaker's eyes, communicate with the client on all matters for clarification, and run the Q/A checks (including analysis and leverage of internal fuzzies), making final changes as necessary.
This is perhaps even the most efficient way to run a process that focuses on and maintains consistency during the job since one person stays responsible for these aspects throughout. A client's project manager can conceivably do this too, but without Korean skills, that person will struggle to fill in all the cracks along the way, even if skilled in the CAT software and efficient workflows.
I also believe that style guides and glossaries should be viewed as living documents, to be finalized at the end of the project. Just because a particular term seems right when setting out doesn't mean one won't get better ideas while working on the job. Sending out lists of high-frequency translation units at the beginning of a project is a good way to support consistency in later work, but only if these can be reconsidered at the end of the project and updated as necessary. Everything can't be set in stone at the beginning; a final consistency review and update at the end will help to tie things together. This is an extra value-add, though.
Failure Point #5 – Wasting resources on inefficient review steps and ignoring vital Q/A tasks and processes
Translation errors can crop up anywhere. In fact, it often takes multiple sets of eyes and an adequate in-context review effort to spot these mistakes. However, even with competent and properly compensated resources at this stage, the process can make all the difference.
I find that some clients introduce an additional review step the sneaky way… by demanding additional work without paying for it. This is done by sending a proofread job back to the translator to be "validated", meaning that the translator checks each of the proofreader's changes and prepares a final version. I generally insist on billing for this review (See On Charging for Additional Translation Reviews.) and it loses me business sometimes. But I also don't think this is an efficient way to handle the review process anyway, especially if there are more steps to go, such as layout.
It has become clear to me that the differences between Korean and English are so great that true fluency is virtually unachievable if second-language learning begins later in life. I've also found (at least with Korean and English) that those born into a bilingual environment and who don't go through the pain of learning a new language the hard way often don't appreciate the necessity of achieving translation precision through careful text analysis. This is further exacerbated by the low opinion Koreans often have of translation as a profession (See About Koreans and Their Attitudes Toward Translators.), leading some who might thrive in this field to move on to more "respectable work".
How many times have you scrutinized the same text several times and overlooked an obvious error that someone else would notice right away? (That's sure to have happened to me several times in this article!) This is, of course, why multiple linguists are brought into a project. However, if the translator, proofreader and quality-assurance professionals are too similar in certain ways (such as by being native Korean speakers with a good, but not perfect grasp of English), they may all miss the same issues. (BTW, the same problem happens in a different way in translation/back-translation workflows.) In my various translation tips, I've pointed out repeated examples of things Korean translators tend to overlook (including punctuation, acronyms, tildes, more acronyms, capitalization). So, just throwing on more layers of review is not a sure-fire way to squeeze out the most quality if the same blind spots remain.
Example Error from Microsoft
Consider the following Korean translation error on the Windows 7 dialogue box that appeared when cleaning out the Recycle Bin:

The problematic text (circled in red) says "source copy" in Korean, but this has absolutely no connection whatsoever to the text that should appear there. This is just the familiar dialogue box telling the user about how many items are being deleted from the Recycle Bin and the word "from" appears at that spot in the English version of Windows 7.
How did this unrelated text creep into the dialogue box? Perhaps Microsoft sent off for translation an Excel file consisting of thousands of context-less interface messages without screenshots or maybe the translators were in a hurry because of an early deadline (or just wanting to finish and collect payment). Or maybe the mistake slipped in later and didn’t get noticed because corners were cut in the review steps.
How persistent can these types of translation errors in software or GUIs be? I found this one after Windows 7 had been out for about three years and this isn't even an obscure window. When I posted it to my weblog, Microsoft contacted me to say they finally fixed it thanks to my article.
* For my original article about this, see There's a Translation Error in the Korean-Language Windows 7 Interface, Too!
Example Error from Google
Here is an example of the kind of mistranslation a native English-speaker review would catch easily. My Android phone has the following menu item:

The tab labelled “설정 진입” literally translates as "Settings Entry" because the first word (“설정”) means “settings” while the second word (“진입”) means "entry, penetration, enter, penetrate". But what is this "Settings Entry" tab supposed to do? The tab has a clearer meaning in the English interface as “Settings Shortcuts.” Apparently, the translator couldn’t think of the right word here. But Korean has a perfectly suitable translation for "shortcut" and this tab should be corrected to “설정 단축 키”.
A better translator might have chosen the more accurate choice of Korean words the first time. But even if not, one of the follow-up reviews should have caught it.
* For my original article about this, see I'm Pretty Sure this Korean Translation Error in the Google Android Interface Came from Google.
Rethinking the Process
I have been experimenting recently with adding an additional review workflow to some projects for my best clients where I myself do a word-for-word proof of the entire English to Korean translation my team sends me after they've finished their translation and proofreading. To be honest, I'm surprised how much I have improved our deliveries by making this sizable additional investment of time.
For sure, a second proofreading step can only contribute to improvements anyway. I mean, is it really fair to expect a proofreader to catch every mistranslation, improve styling, check for terminology consistency, notice each and every typo (and not create a couple more while improving styling) and, where applicable, thoroughly consider localization factors, such as cultural appropriateness, even while making sense of phrases out of context and embedded variables, and do it all in one workflow?
But beyond all that, my English native-speaker eyes catch mistranslations that the eyes of a Korean overlook. (For examples, see English>Korean Translation Errors Discovered Through a Proofreading Step Performed by a Native English-Speaker Translator Who Usually Handles Korean>English Translation Work.) This value-add is in addition to the stylistic matters Koreans tend to let slip by. By dedicating one workflow to issues the Korean team may miss, as well as to intra-team and team-client communications, the communication phase is condensed into a single project stage and allows the Korean team to maintain extended focus during the translation and first proofreading steps.
The extra workflow also takes the burden off the Koreans to even ask those questions. Who wants to interrupt a train of thought to send off questions for later replies in the middle of working on a document? Ideally, translators will ask anyway, but in practice, I've found it rarely gets done, especially if the linguists are afraid of exposing their ignorance on something they should have known. (I can comment on this with confidence because I experience the same thought process on my own Korean>English translations jobs, too!)
This extra proofreading step is a frustratingly time-consuming task because of all the time it takes to work things out, but it can be combined with the various Q/A work in the CAT tool to also take other burdens off the translator and proofreader (such as perfect consistency) who may be subject-matter experts but not fans of the technology.
I've alluded above to the issue of an inefficient review step demanded of translators by some clients. But rather than creating a new workflow just to check the work of a proofreader, it would be better to integrate this additional check into the final post-layout proof and other quality assurance tasks, which need to be done anyway. Every additional workflow incurs costs (Check out Getting Things Done by David Allen for an excellent book about personal efficiency and the hidden costs of individual tasks, even small ones!) and each step is an opportunity to get files confused, introduce new errors or miss deadlines. Combining work here is surely recommended, especially as the post-layout environment is different than the translation environment (it's a different screen) and so helps to bring a new perspective on the text rather than just going back to the same document with the same blind spots again. Having all this done by someone other than the translator and proofreader mixes things up yet again, to avoid these blind spots.
Conclusion
As shown above, even leading companies don’t always get the localization process right and I can tell you that the Korean translations of many of the mobile apps on Google Play created by smaller providers are almost incomprehensible when handled through Google Translate or some other cut-rate approach.
There are so many subjective aspects to translation that it may not be realistic to talk about a "100% perfect" translation; what one person considers a bit stilted may be what another views as a very precise and correct rendering. And even if we can get away with using numbers, 100% on a large project may still be out of reach. But getting from 98% to 99.5% is a worthy improvement that can be achieved by thinking outside the box and applying more effective and realistic roles and workflows.
Of course, it's worth asking if a client is willing to make the investment to achieve this level of improvement, especially considering that many errors remain invisible to the end without causing any grief to anyone (case in point: that translation error I mentioned above that remained in Windows 7 for three years before anyone bothered to fix it). In fact, the current three-step workflow has worked fine for us over the years, too.
Still, I'd like to think that we can do better and my goal is to develop workflows with my team that take advantage of all the resources at our disposal to deliver even better work than ever before and to do it without putting undo strain on clients and their budgets. I hope to release new workflow designs soon.